
Posez votre question et obtenez un résumé du document en referencant cette page et le Provider AI de votre choix
Le contenu de cette page a été traduit à l'aide d'une IA.
Voir la dernière version du contenu original en anglaisIf you have an idea for improving this documentation, please feel free to contribute by submitting a pull request on GitHub.
GitHub link to the documentationCopy doc Markdown to clipboard
i18n par composant vs. i18n centralisé
L'approche par composant n'est pas un concept nouveau. Par exemple, dans l'écosystème Vue, vue-i18n prend en charge l'i18n SFC (Single File Component). Nuxt propose également des traductions par composant, et Angular utilise un modèle similaire via ses Feature Modules.
Même dans une application Flutter, on retrouve souvent ce schéma :
Copier le code dans le presse-papiers
lib/└── features/ └── login/ ├── login_screen.dart └── login_screen.i18n.dart # <- Les traductions se trouvent iciCopier le code dans le presse-papiers
import 'package:i18n_extension/i18n_extension.dart';extension Localization on String { static var _t = Translations.byText("en") + { "Hello": { "en": "Hello", "fr": "Bonjour", }, }; String get i18n => localize(this, _t);}Cependant, dans le monde React, on observe principalement différentes approches que je regrouperai en trois catégories :
Approche centralisée (i18next, next-intl, react-intl, lingui)
- (sans namespaces) considère une seule source pour récupérer le contenu. Par défaut, vous chargez le contenu de toutes les pages lorsque votre application se charge.
Approche granulaire (intlayer, inlang)
- affiner la récupération du contenu par clé ou par composant.
Dans ce blog, je ne me concentrerai pas sur les solutions basées sur un compilateur, que j'ai déjà abordées ici : Compilateur vs i18n déclaratif. Notez que l'i18n basée sur un compilateur (par exemple, Lingui) n'automatise que l'extraction et le chargement du contenu. Sous le capot, ces solutions partagent souvent les mêmes limitations que les autres approches.
Notez que plus vous affinez la façon dont vous récupérez votre contenu, plus vous risquez d'introduire de l'état et de la logique supplémentaires dans vos composants.
Les approches granulaires sont plus flexibles que les approches centralisées, mais c'est souvent un compromis. Même si ces bibliothèques mettent en avant le "tree shaking", en pratique vous finirez souvent par charger une page dans chaque langue.
Donc, de manière générale, la décision se résume ainsi :
- Si votre application a plus de pages que de langues, vous devriez privilégier une approche granulaire.
- Si vous avez plus de langues que de pages, vous devriez opter pour une approche centralisée.
Bien sûr, les auteurs des bibliothèques sont conscients de ces limites et proposent des solutions de contournement. Parmi elles : scinder en namespaces, charger dynamiquement des fichiers JSON (await import()), ou purger le contenu lors du build.
En même temps, vous devez savoir que lorsque vous chargez dynamiquement votre contenu, vous introduisez des requêtes supplémentaires vers votre serveur. Chaque useState supplémentaire ou hook signifie une requête serveur supplémentaire.
Pour résoudre ce point, Intlayer suggère de regrouper plusieurs définitions de contenu sous une même clé ; Intlayer fusionnera ensuite ce contenu.
Mais parmi toutes ces solutions, il est clair que l'approche centralisée est la plus populaire.
Alors, pourquoi l'approche centralisée est-elle si populaire ?
- Tout d'abord, i18next a été la première solution à devenir largement utilisée, suivant une philosophie inspirée des architectures PHP et Java (MVC), qui reposent sur une stricte séparation des préoccupations (garder le contenu séparé du code). Elle est arrivée en 2011, établissant ses standards bien avant le passage massif aux architectures basées sur les composants (comme React).
- Ensuite, une fois qu'une bibliothèque est largement adoptée, il devient difficile de faire évoluer l'écosystème vers d'autres approches.
- L'utilisation d'une approche centralisée facilite également l'intégration avec des systèmes de gestion de traduction tels que Crowdin, Phrase ou Localized.
- La logique d'une approche par composant est plus complexe que celle d'une approche centralisée et demande plus de temps de développement, surtout lorsqu'il faut résoudre des problèmes comme l'identification de l'emplacement du contenu.
Ok, mais pourquoi ne pas simplement rester sur une approche centralisée ?
Laissez-moi vous expliquer pourquoi cela peut poser problème pour votre application :
- Données inutilisées : Lorsque une page se charge, vous chargez souvent le contenu de toutes les autres pages. (Dans une application de 10 pages, cela représente 90 % de contenu inutile chargé). Vous chargez un modal en lazy load ? La bibliothèque i18n s'en fiche, elle charge d'abord les chaînes de toute façon.
- Performances : À chaque re-render, chacun de vos composants est hydraté avec une charge JSON massive, ce qui affecte la réactivité de votre application à mesure qu'elle grandit.
- Maintenance : Maintenir de gros fichiers JSON est pénible. Vous devez sauter d'un fichier à l'autre pour insérer une traduction, en vous assurant qu'aucune traduction ne manque et qu'aucune clé orpheline ne subsiste.
- Design-system :
Cela crée une incompatibilité avec les design systems (par exemple, un composant
LoginForm) et limite la duplication de composants entre différentes applications.
"Mais nous avons inventé Namespaces !"
Bien sûr, et c'est une avancée majeure. Regardons la comparaison de la taille du bundle principal d'une configuration Vite + React + React Router v7 + Intlayer. Nous avons simulé une application de 20 pages.
Le premier exemple n'inclut pas de traductions chargées à la demande par locale et aucune séparation en namespaces. Le second inclut une purge du contenu + chargement dynamique des traductions.
Ouvrir le tableau dans une fenêtre modale pour voir tout le contenu clairement
| Bundle optimisé | Bundle non optimisé |
|---|---|
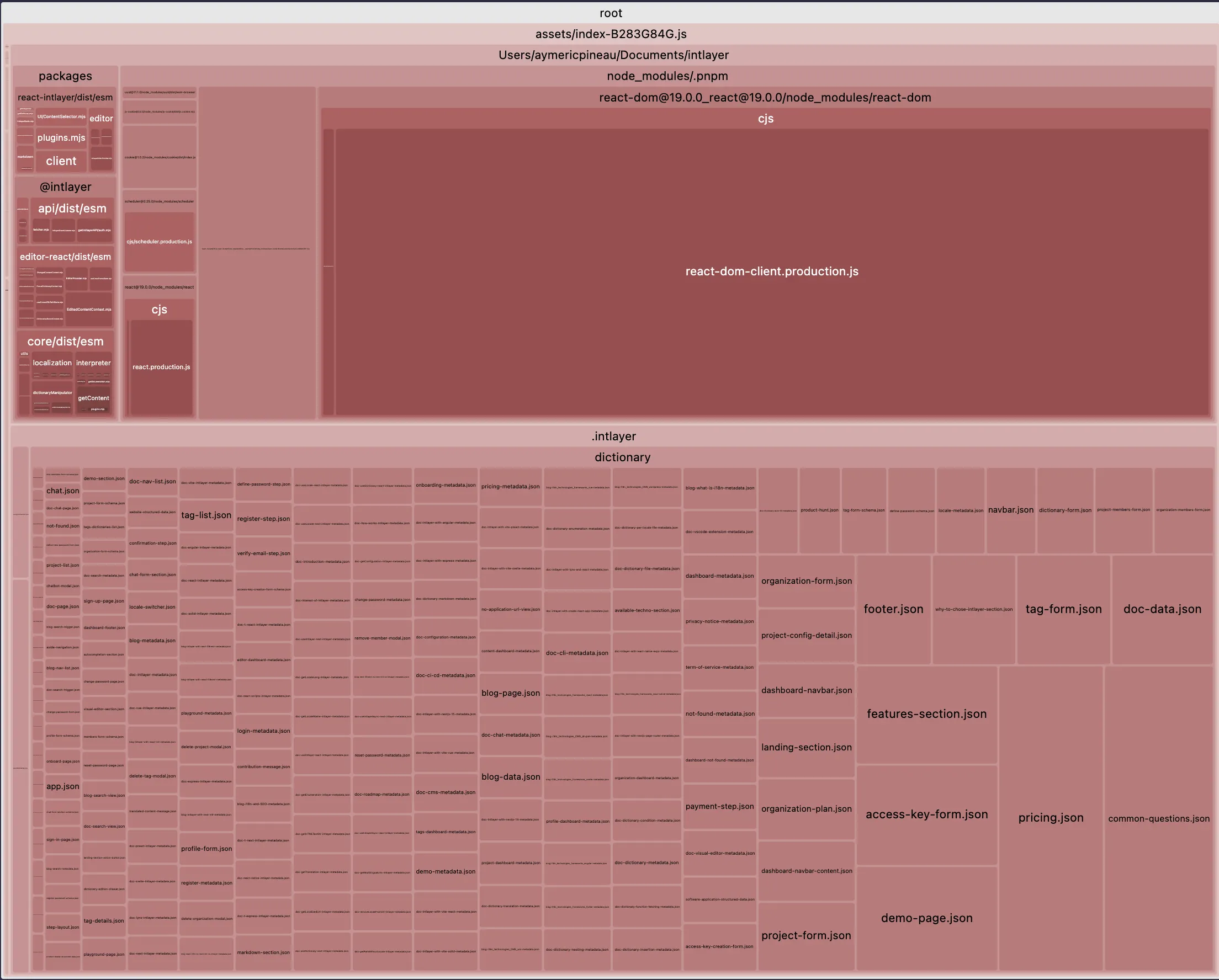 | 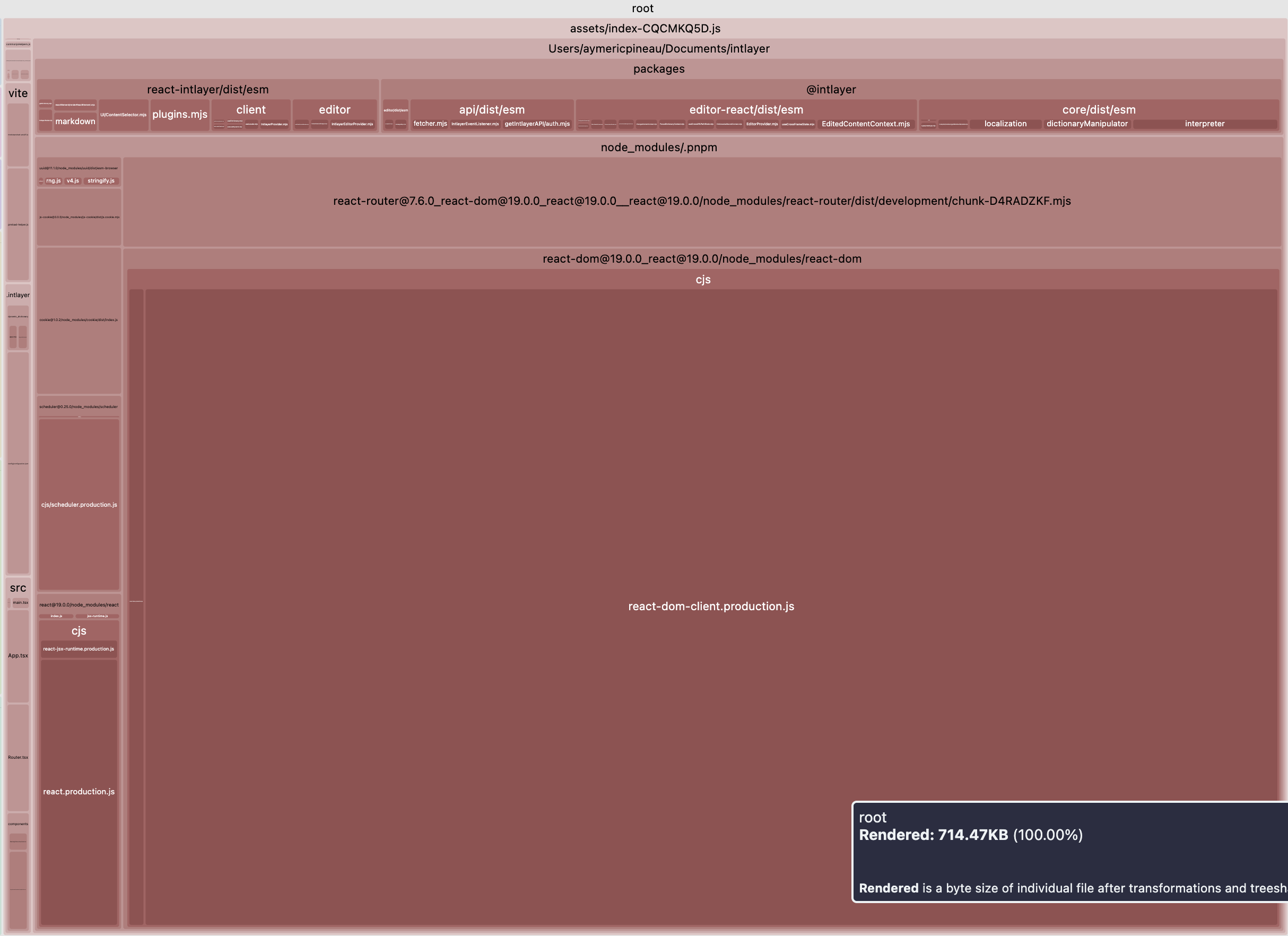 |
Donc, grâce aux namespaces, nous sommes passés de cette structure :
Copier le code dans le presse-papiers
locale/├── en.json├── fr.json└── es.jsonÀ celle-ci :
Copier le code dans le presse-papiers
locale/├── en/│ ├── common.json│ ├── navbar.json│ ├── footer.json│ ├── home.json│ └── about.json├── fr/│ └── ...└── es/ └── ...Vous devez maintenant gérer avec précision quelles parties du contenu de votre application doivent être chargées, et où. En conclusion, la grande majorité des projets passent simplement outre cette étape en raison de la complexité (voir par exemple le guide next-i18next pour constater les défis que représente (simplement) le suivi des bonnes pratiques).
Notez que ce problème n'est pas spécifique à i18next, mais concerne toutes les approches centralisées listées ci‑dessus.
Cependant, je tiens à vous rappeler que toutes les approches granulaires ne résolvent pas ce problème. Par exemple, les approches vue-i18n SFC ou inlang ne réalisent pas automatiquement le lazy loading des traductions par locale, vous échangez ainsi le problème de la taille du bundle contre un autre.
De plus, sans une séparation des préoccupations appropriée, il devient beaucoup plus difficile d'extraire et de fournir vos traductions aux traducteurs pour relecture.
Comment l'approche par composant d'Intlayer résout ce problème
Intlayer procède en plusieurs étapes :
- Déclaration : Déclarez votre contenu n'importe où dans votre codebase en utilisant des fichiers
*.content.{ts|jsx|cjs|json|json5|...}. Cela garantit la séparation des préoccupations tout en gardant le contenu colocé à proximité du code. Un fichier de contenu peut être par-locale ou multilingue. - Traitement : Intlayer exécute une étape de build pour traiter la logique JS, gérer les traductions manquantes (fallbacks), générer des types TypeScript, gérer le contenu dupliqué, récupérer le contenu depuis votre CMS, et plus encore.
- Purge : Lors du build de votre application, Intlayer purge le contenu inutilisé (un peu comme Tailwind gère vos classes) en remplaçant le contenu comme suit :
Déclaration :
Copier le code dans le presse-papiers
// src/MyComponent.tsxexport const MyComponent = () => { const content = useIntlayer("my-key"); return <h1>{content.title}</h1>;};Copier le code dans le presse-papiers
// src/myComponent.content.tsexport const { key: "my-key", content: t({ fr: { title: "Mon titre" }, en: { title: "My title" } })}Traitement : Intlayer construit le dictionnaire à partir du fichier .content et génère :
Copier le code dans le presse-papiers
// .intlayer/dynamic_dictionary/fr/my-key.json{ "key": "my-key", "content": { "title": "Mon titre" },}Remplacement : intlayer extracte votre composant lors du build de l'application.
- Mode d'import statique :
Copier le code dans le presse-papiers
// Représentation du composant en syntaxe de type JSXexport const MyComponent = () => { const content = useDictionary({ key: "my-key", content: { nodeType: "translation", translation: { en: { title: "My title" }, fr: { title: "Mon titre" }, }, }, }); return <h1>{content.title}</h1>;};- Mode d'import dynamique :
Copier le code dans le presse-papiers
// Représentation du composant en syntaxe de type JSXexport const MyComponent = () => { const content = useDictionaryAsync({ en: () => import(".intlayer/dynamic_dictionary/en/my-key.json", { with: { type: "json" }, }).then((mod) => mod.default), // Idem pour les autres langues }); return <h1>{content.title}</h1>;};useDictionaryAsync utilise un mécanisme de type Suspense pour charger le JSON localisé uniquement lorsque c'est nécessaire.Principaux avantages de cette approche par composant :
Garder la déclaration de votre contenu proche de vos composants permet une meilleure maintenabilité (p.ex. déplacer un composant vers une autre application ou design system. La suppression du dossier du composant supprime également le contenu associé, comme vous le faites probablement déjà pour vos fichiers
.testet.stories)Une approche par composant évite que les agents IA aient besoin de parcourir tous vos fichiers. Elle regroupe toutes les traductions au même endroit, limitant la complexité de la tâche et la quantité de tokens utilisés.
Limitations
Bien sûr, cette approche implique des compromis :
- Il est plus difficile de se connecter à d'autres systèmes de l10n et à des outils supplémentaires.
- Cela entraîne un lock-in (ce qui est déjà le cas avec toute solution i18n en raison de leur syntaxe spécifique).
C'est pourquoi Intlayer cherche à fournir un ensemble d'outils complet pour l'i18n (100 % gratuit et OSS), incluant la traduction par IA en utilisant votre propre fournisseur d'IA et vos clés API. Intlayer fournit aussi des outils pour synchroniser vos JSON, fonctionnant comme les formatters de messages ICU / vue-i18n / i18next pour mapper le contenu vers leurs formats spécifiques.
Commentaires
Aucun commentaire pour le moment. Soyez le premier à partager vos pensées.